데이터베이스의 기본
데이터베이스 (DB, DataBase)
- 일정한 규칙, 혹은 규약을 통해 구조화되어 저장되는 데이터의 모음
- 특정 조직의 업무를 수행하는 데 필요한 상호 관련된 데이터들의 모임
- 여러 사람들이 공유하는 사용할 목적으로 통합 관리되는 데이터들의 모임
DBMS (DataBase Management System)
- 해당 데이터베이스를 제어, 관리하는 통합 시스템
- DBMS를 통해 데이터베이스를 관리하여 응용 프로그램들이 데이터베이스를 공유하고, 사용할 수 있는 환경을 제공
- 데이터베이스 안에 있는 데이터들은 특정 DBMS마다 정의된 쿼리 언어(query language)를 통해 삽입, 삭제, 수정, 조회 등을 수행할 수 있다.
※ DBMS의 기능
1) 데이터 정의 - 데이터에 대한 형식, 구조, 제약조건들을 명세하는 기능
2) 데이터 조작 - 특정한 데이터를 검색하기 위한 질의, 데이터베이스의 갱신, 보고서 생성 기능
3) 데이터 제어
- 데이터 무결성(Integrity)
- 보안(Security) / 권한(Authority) 검사
- 동시성 제어(Concurrency Control)
4) 데이터 공유 - 여러 사용자와 프로그램이 데이터베이스에 동시에 접근하도록 하는 기능
5) 데이터 보호 - 하드웨어나 소프트웨어의 오동작 또는 권한이 없는 악의적인 접근으로부터 시스템을 보호
6) 데이터 구축 - DBMS가 관리하는 기억 장치에 데이터를 저장하는 기능
7) 유지보수 - 시간이 지남에 따라 변화하는 요구사항을 반영할 수 있도록 하는 기능
※ DBMS의 종류
1) 계층형(Hierarchical DataBase)
- 데이터 간의 관계가 트리 형태의 구조
2) 네트워크형(Network DataBase)
- 계층형 데이터베이스의 단점을 보완하여 데이터 간 N:N(다대다) 구성이 가능한 망형 모델
- CODASYL이 제안한 것으로, CODASYL DBTG모델이라고도 한다.
3) 관계형(Relational DataBase)
- 키(Key)와 값(Value)으로 이루어진 데이터들을 행(Row)과 열(Column)로 구성된 테이블 구조로 단순화시킨 모델
4) 객체 지향형(Object-Oriented DataBase)
- 객체지향 프로그래밍 개념에 기반하여 만든 데이터베이스 모델
- 비정형 데이터들을 데이터베이스화할 수 있도록 하기 위해 만들어진 모델
5) 객체 관계형(Object-Relational DataBase)
- 관계형 데이터베이스에 객체 지향 개념을 도입하여 만든 데이터베이스 모델
6) NoSQL
- Not Only SQL의 줄임말로 SQL뿐만 아니라 다양한 특성을 지원한다는 의미
7) NewSQL
- RDBMS의 SQL과 NoSQL의 장점을 결합한 관계형 모델
엔터티
엔터티(개체, Entity)
- 데이터베이스에 데이터로 표현하려고 하는 현실 세계의 대상체
- 저장할 만한 가치가 있는 중요 데이터를 가지고 있는 사람이나 사물 등
- 서비스의 요구 사항에 맞춰 속성이 정해진다.
※ 약한 엔터티와 강한 엔터티
A가 혼자서는 존재하지 못하고 다른 것(B)의 존재 여부에 따라 종속적일 때 A는 약한 엔터티, B는 강한 엔터티
릴레이션
릴레이션(Relation)
- 정보를 구분하여 저장하는 기본 단위
- 관계형 데이터베이스에서는 '테이블', NoSQL 데이터베이스에서는 '컬렉션'
※ 릴레이션
- 데이터들을 2차원 테이블의 구조로 저장한 것
릴레이션의 구성
- 릴레이션 스키마 : 릴레이션 이름과 릴레이션에 포함된 모든 속성의 이름으로 정의하는 릴레이션의 논리적인 구조
- 릴레이션 인스턴스 : 릴레이션 스키마에 실제로 저장된 데이터의 집합
릴레이션의 특징
- 튜플의 유일성 : 릴레이션 안에는 똑같은 튜플이 존재할 수 없음
- 튜플의 무순서성 : 튜플 사이에는 순서가 없음
- 속성의 무순서성 : 속성 사이에는 순서가 없음
- 속성의 원자성 : 속성은 더 이상 분해할 수 없는 원자값만 가진다.
- 튜플들의 삽입, 갱신, 삭제작업이 실시간으로 일어나므로 릴레이션은 수시로 변한다.
속성
속성(Attribute)
- 릴레이션에서 관리하는 구체적이며 고유한 이름을 갖는 정보
- 서비스의 요구 사항을 기반으로 관리해야 할 필요가 잇는 속성들만 엔터티의 속성이 된다.
- 릴레이션의 각 열을 속성 또는 Attribute라고 한다.
- 데이터를 구성하는 가장 작은 논리적인 단위
- 개체의 특성을 기술
- 속성의 수 = 디그리(Degree) = 차수
도메인
도메인
- 하나의 속성이 가질 수 있는 값의 범위
필드와 레코드
필드는 속성과 비슷하다
※ 필드타입
- 숫자 타입
| 타입 | 용량(바이트) | 최솟값(부호 있음) | 최솟값(부호 없음) | 최댓값(부호 있음) | 최댓값(부호 없음) |
| TINYINT | 1 | -128 | 0 | 127 | 255 |
| SMALLINT | 2 | -32768 | 0 | 32767 | 65535 |
| MEDIUMINT | 3 | -8388608 | 0 | 8388607 | 16777215 |
| INT | 4 | -2147483648 | 0 | 2147483647 | 4294967295 |
| BIGINT | 8 | -2^63 (-92233720036854775808) |
0 | 2^63-1 (92233720036854775807) |
2^64-1 (18446744073709551615) |
- 날짜 타입
DATE : 날짜 부분은 있지만 시간 부분은 없는 값에 사용, 1000-01-01 ~ 9999-12-31, 3바이트
DATETIME : 날짜 및 시간 부분을 모두 포함하는 값에 사용, 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59, 8바이트
TIMESTAMP : 날짜 및 시간 부분을 모두 포함하는 값에 사용, 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07, 4바이트
- 문자 타입
CHAR
: 고정 길이의 문자열, 길이는 0에서 255 사이의 값, 레코드를 저장할 때 무조건 선언한 길이 값으로 '고정'해서 저장된다.
VARCHAR
: 가변 길이 문자열, 길이는 0에서 65,535 사이의 값, 입력된 데이터에 따라 용량을 가변시켜 저장
TEXT
: 큰 문자열 저장에 쓰며 주로 게시판의 본문을 저장할 때 사용
BLOB
: 이미지, 동영상 등 큰 데이터 저장에 사용
ENUM
: ENUM 리스트로 설정한 것 중 단일 선택만 가능, ENUM 리스트에 없는 잘못된 값을 삽입하면 빈 문자열이 대신 삽입된다.
설정된 값들이 0,1 등으로 매핑되어 메모리를 적게 사용한다.
최대 65,535개의 요소들을 넣을 수 있다.
SET
: ENUM과 비슷하지만 여러 개의 데이터를 선택할 수 있고 비트 단위의 연산을 할 수 있으며 최대 64개의 요소를 집어넣을 수 있다.
(ENUM 이나 SET을 쓸 경우 공간적으로 이점을 얻을 수 있지만 애플리케이션 수정에 따라 DB의 ENUM이나 SET에서 정의한 목록을 수정해야 한다는 단점이 존재)
레코드
- 릴레이션의 행(row)
- 튜플(Tuple)이라고도 함
- 튜플의 수 = 카디널리티(Cardinality) = 기수
그외 용어들
차수(Degree)
- 하나의 릴레이션에서 속성의 전체 개수
카디널리티(Cardinality)
- 하나의 릴레이션에서 튜플의 전체 개수
관계
관계(Relationship)
- 서로 다른 개체가 맺고 있는 의미 있는 연관성
- 1:1 개체 집합 A의 원소가 개체 집합 B의 원소 1개와 대응
- 1:N 개체 집합 A의 각 원소는 개체 집합 B의 원소 여러 개와 대응할 수 있고, 개체 집합 B의 각 원소는 개체 집합 A의 원소 1개와 대응
- N:M 개체 집합 A의 각 원소는 개체 집합 B의 원소 여러 개와 대응할 수 있고, 개체 집합 B의 각 원소도 개체 집합 A의 원소 여러 개와 대응
새발(Crow-feet) 표기법

N:M은 테이블 두 개를 직접적으로 연결해서 구축하지 않고, 1:N, 1:M 관계를 갖는 테이블 두 개로 나눠서 설정
키
키(Key)의 개념
- 릴레이션에서 다른 튜플들과 구별할 수 있는 유일한 기준이 되는 컬럼
키(Key)의 종류
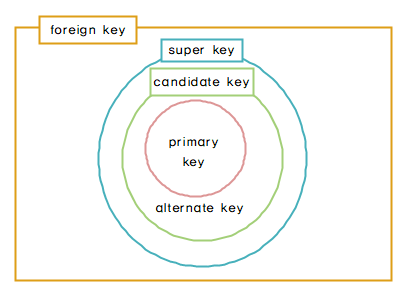
1) 후보키(Candidate Key)
- 릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별할 수 있는 속성들의 부분집합
- 모든 릴레이션은 반드시 하나 이상의 후보키를 가져야 한다.
- 튜플에 대한 유일성과 최소성을 만족시켜야 한다.
2) 기본키(Primary Key)
- 후보키 중에서 선택한 주키(Main Key)
- 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성
- Null 값을 가질 수 없다.(개체 무결성)
- 기본키로 정의된 속성에는 동일한 값이 중복되어 저장될 수 없다.(개체 무결성)
- 기본키는 자연키 또는 인조키 중 설정
유일성? 최소성?
유일성 : 릴레이션 안에는 똑같은 튜플이 존재할 수 없음
최소성 : 필드를 조합하지 않고 최소 필드만 써서 키를 형성할 수 있는 것.
(하나의 속성으로도 기본키로 사용이 가능할 때 다른 속성과 함께 묶여 기본키로 사용되었을 경우 유일성은 만족할 수 있지만 최소성을 만족할 수 없다.)
자연키? 인조키?
자연키 : 중복된 값들을 제외하며 중복되지 않는 것을 '자연스레' 뽑다가 나오는 키, 언젠가 변하는 속성을 지닌다.
인조키 : 인위적으로 셍성한 키, 변하지 않기 때문에 보통 기본키는 인조키로 설정한다.
3) 대체키(Alternate Key)
- 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키
4) 슈퍼키(Super Key)
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키
- 튜플에 대한 유일성은 만족하지만, 최소성은 만족시키지 못한다.
5) 외래키(Foreign Key)
- 관계(Relation)를 맺고 있는 릴레이션 R1, R2에서 릴레이션 R1이 참조하고 있는 릴레이션 R2의 기본키와 같은 R1 릴레이션의 속성
- 참조되는 릴레이션의 기본키와 대응되어 릴레이션 간에 참조 관계를 표현하는 데 중요한 도구로 사용
- 외래키로 지정되면 참조 테이블의 기본키에 없는 값은 입력할 수 없다.(참조 무결성 조건)
- 중복 가능
무결성?
데이터베이스 무결성 개념
- 데이터의 정확성, 일관성, 유효성이 유지되는 것
데이터베이스 무결성 종류
1) 개체 무결성(Entity Integrity)
- 모든 릴레이션은 기본 키(Primary Key)를 가져야 한다.
- 기본키는 중복되지 않은 고유한 값을 가져야 한다.
- 릴레이션의 기본키는 NULL 값을 허용하지 않는다.
2) 참조 무결성(Referential Integrity)
- 외래키 값은 NULL이거나 참조하는 릴레이션의 기본키 값과 동일해야 한다.
- 각 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다.
참조 무결성 제약조건
| 제약조건 | 설명 |
| 제한(Restrict) | 문제가 되는 연산을 거절 |
| 연쇄(Cascade) | 부모 릴레이션에서 튜플을 삭제하면 자식 릴레이션에서 이 튜플을 참조하는 튜플도 함께 삭제 |
| 널값(Nullify) | 부모 릴레이션에서 튜플을 삭제하면 자식 릴레이션에서 이 튜플을 참조하는 튜플들의 외래키에 NULL 등록 |
| 기본값(Default) | Null을 넣는 대신에 디폴트 값을 등록 |
3) 도메인 무결성(Domain Integrity)
- 속성들의 값은 정의된 도메인에 속한 값이어야 한다.
- 성별이라는 컬럼에는 ‘남’, ‘여’를 제외한 데이터는 제한되어야 한다.
4) 고유 무결성(Unique Integrity)
- 릴레이션의 특정 속성에 대해 각 튜플이 갖는 속성 값들이 서로 달라야 한다.
5) 키 무결성(Key Integrity)
- 하나의 릴레이션에는 적어도 하나의 키가 존재해야 한다.
6) 릴레이션 무결성(Relation Integrity)
- 삽입, 삭제, 갱신과 같은 연산을 수행하기 전과 후에 대한 상태의 제약
ERD와 정규화 과정
ERD(Entity Relationship Diagram)
- 릴레이션 간의 관계를 정의한 것
- 관계형 구조로 표현할 수 있는 데이터를 구성하는 데 유용할 수 있지만 비정형 데이터를 충분히 표현할 수 없다.
(비정형 데이터 : 비구조화 데이터를 말하며, 미리 정의된 데이터 모델이 없거나 미리 정의된 방식으로 정리되지 않은 정보를 말한다.
정규화 과정
정규화의 개념
- 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화
정규화의 목적
- 데이터의 중복을 최소화
- 정보의 무손실 : 정보가 사라지지 않아야 함
- 독립적인 관계는 별개의 릴레이션으로 표현
- 정보의 검색을 보다 용이하게 함
- 이상 현상 최소화
정규화의 장/단점
| 장점 | - 데이터 중복의 최소화 - 저장 공간의 효율적 사용 - 릴레이션에서 발생 가능한 이상 현상 제거 |
| 단점 | - 처리 명령의 복잡 - 실행 속도 저하 - 분리된 두 릴레이션 간 참조 무결성 유지를 위한 노력 필요 - 분리된 여러 개의 테이블에서 정보를 취합하기 위한 JOIN 연산이 필요 |
이상 현상(Anomaly)
- 데이터 중복으로 인해 릴레이션 조작 시 예상하지 못한 곤란한 현상이 발생
- 이상의 종류
① 삽입 이상 : 데이터를 삽입할 때 불필요한 데이터가 함께 삽입되는 현상
② 삭제 이상 : 한 튜플을 삭제할 때 연쇄 삭제 현상으로 인해 정보 손실
③ 갱신 이상 : 튜플의 속성값을 갱신할 때 일부 튜플의 정보만 갱신되어 정보에 모순이 생기는 현상
함수적 종속(Functional Dependency)
1) 함수적 종속의 개념
- 어떤 릴레이션 R의 X와 Y를 각각 속성의 부분집합이라고 가정했을 때
--- X의 값을 알면 Y의 값을 바로 식별할 수 있고, X의 값에 Y의 값이 달라질 때, Y는 X에 함수적 종속이라고 함
--- 이를 기호로 표현하면 X→Y
2) 함수적 종속 관계
- 완전 함수적 종속(Full Functional Dependency)
종속자가 기본키에만 종속되며, 기본키가 여러 속성으로 구성되어 있을 때, 기본키를 구성하는 모든 속성이 포함된 기본키의 부분집합에 종속된 경우
- 부분 함수적 종속(Partial Functional Dependency)
기본키가 여러 속성으로 구성되어 있을 때, 기본키를 구성하는 속성 중 일부만 종속되는 경우
기본키가 두개일 때 부분 함수 종속
| 회원 번호 | 강의 코드 | 강의명 | 강의 점수 |
| M001 | P001 | 미시경제학 | 80 |
| M002 | P002 | 거시경제학 | 70 |
| M003 | P003 | 재정학 | 80 |
| M004 | P004 | 개방거시경제학 | 100 |
위 릴레이션에서 강의점수는 기본키(회원번호+강의코드)에 종속적이지만, 강의명은 강의 코드에만 종속된다.
강의명이 부분 함수 종속된 관계
- 이행적 함수 종속(Transitive Functional Dependecy)
X→Y, Y→Z 이러한 종속 관계가 있을 경우, X→Z가 성립되는 경우
| 학번 | 주민번호 | 이름 |
| 001 | 1111 | 영희 |
| 002 | 2222 | 철수 |
| 003 | 3333 | 민수 |
정규화 과정
기본 정규형 : 제 1정규형, 제 2정규형, 제3정규형, 보이스/코드 정규형
고급 정규형 : 제 4정규형, 제 5정규형
1) 제 1정규형(1NF)
- 어떤 릴레이션에 속한 모든 도메인이 원자값만으로 되어 있다.
- 한 개의 기본키에 대해 두 개 이상의 값을 가지는 반복 집합이 있어서는 안된다.
| 고객 번호 | 이름 | 여행지 |
| 001 | 철수 | 서울 |
| 002 | 영희 | 서울, 인천 |
| 003 | 민수 | 인천, 광주, 부산 |
| 고객 번호 | 이름 |
| 001 | 철수 |
| 002 | 영희 |
| 003 | 민수 |
| 고객 번호 | 여행지 |
| 001 | 서울 |
| 002 | 서울 |
| 002 | 인천 |
| 003 | 인천 |
| 003 | 광주 |
| 003 | 부산 |
2) 제 2정규형(2NF)
- 부분 함수적 종속을 모두 제거하여 완전 함수적 종속으로 만든다.
| 회원 번호 | 강의 코드 | 강의명 | 강의 점수 |
| M001 | P001 | 미시경제학 | 80 |
| M002 | P002 | 거시경제학 | 70 |
| M003 | P003 | 재정학 | 80 |
| M004 | P004 | 개방거시경제학 | 100 |
| 강의 코드 | 강의명 |
| P001 | 미시경제학 |
| P002 | 거시경제학 |
| P003 | 재정학 |
| P004 | 개방거시경제학 |
| 회원 번호 | 강의 코드 | 강의 점수 |
| M001 | P001 | 80 |
| M002 | P002 | 70 |
| M003 | P003 | 80 |
| M004 | P004 | 100 |
- 강의명은 강의 코드만 가지고 알 수 있다.
- 강의 코드와 강의명을 하나의 릴레이션으로 하고, 강의 점수는 회원 번호와 강의 코드가 필요하기 때문에 이릃 하나의 릴레이션으로 구성한다.
3) 제 3정규형(3NF)
- 이행적 함수 종속을 없앤다.
| 학번 | 주민번호 | 이름 |
| 001 | 1111 | 영희 |
| 002 | 2222 | 철수 |
| 003 | 3333 | 민수 |
- 학번을 알면 주민번호를 알 수 있고 주민번호를 알면 이름을 알 수 있다.
- 학번과 주민번호를 하나의 릴레이션으로, 주민번호와 이름을 하나의 릴레이션으로 구성한다.
| 학번 | 주민번호 |
| 001 | 1111 |
| 002 | 2222 |
| 003 | 3333 |
| 주민번호 | 이름 |
| 1111 | 영희 |
| 2222 | 철수 |
| 3333 | 민수 |
4) 보이스/코드(BCNF) 정규형
- 결정자 중 후보키가 아닌 것들을 제거, 릴레이션의 함수 종속 관계에서 모든 결정자가 후보키인 상태
(결정자 : 함수 종속 관계에서 특정 종속자(dependent)를 결정짓는 요소, 'X->Y'일 때 X는 결정자, Y는 종속자이다.)
- 후보키는 최소성과 유일성을 만족해야 한다. 즉 후보키만으로 릴레이션에서 튜플을 특정할 수 있는 능력이 있어야 하며, 유일성을 가지는 데 꼭 필요한 속성들로만 구성되어야 한다,
일반적으로 데이터베이스에서 3NF는 거의 완벽한 수준이고, 데이터베이스의 설계 목표가 3NF를 만드는 것이다.
하지만 간혹 3NF임에도 문제가 있을 수 있다.
| 학번 | 과목 | 교수 |
| 1234 | 데이터베이스 | 김용주 |
| 1234 | 자료구조 | 이우정 |
| 2587 | 프로그래밍 | 박정미 |
| 2587 | 자료구조 | 고현주 |
| 3654 | 데이터베이스 | 김용주 |
◎ 가정
각 교수는 한 과목만 담당한다고 가정
각 수강명에 대해 한 학생은 오직 한 강사의 강의만 수강
한 수강명은 여러 강사가 담당할 수 있다고 가정
함수 종속 관계는 다음과 같다
{학번,과목} -> 교수
교수 -> 과목
위와 같을 때 {학번,과목}과 교수의 관계는 문제 없어 보이지만 교수와 과목의 관계가 불안정하다.
- 삽입 이상
새로운 교수가 새로운 과목을 강의하게 되었을 때 기본키인 학번이 NULL이므로 삽입이 불가능하다
- 삭제 이상
학번이 '1234'인 학생이 '자료구조' 수강을 취소하면 '이용주' 교수가 '자료구조' 수업을 맡고 있다는 정보도 삭제된다.
- 갱신 이상
'김용주' 교수의 강의 과목이 변경되었을 경우 '김용주'에 대한 모든 튜플에 대해 변경되어야 한다. 그렇지 않으면 일관성에 문제가 생긴다.
이를 해결한 것이 보이스/코드 정규형이다.
각 교수는 한 과목만 맡을 수 있으므로 과목 속성에 대해 결정자다.
그렇지만 교수 정보만 가지고는 튜플을 식별할 수 없다. 즉 후보키가 될 수 없다.
교수 속성이 후보키가 될 수 있게 릴레이션을 분할하면 다음과 같다.
| 학번 | 교수 |
| 1234 | 김용주 |
| 1234 | 이우정 |
| 2587 | 박정미 |
| 2587 | 고현주 |
| 3654 | 김용주 |
| 교수 | 과목 |
| 김용주 | 데이터베이스 |
| 이우정 | 자료구조 |
| 박정미 | 프로그래밍 |
| 고현주 | 자료구조 |
5) 제 4정규형(4NF)
- 다치 종속을 제거
6) 제 5정규형(5NF)
- 조인 종속 이용
정규화가 항상 성능이 좋아지는 것은 아니다. 테이블을 나누면 조인이 발생해서 더 느려질 수도 있다. 그럴 경우 반정규화(역정규화)를 해야 한다.
반정규화의 개념
- 시스템의 성능향상과 개발 편의성 등을 위해 정규화에 위배되는 중복을 허용하는 기법
반정규화 시 고려사항
- 데이터의 중복이 발생하여 데이터 수정 시 무결성이 깨질 수 있다.
- 읽기 속도는 향상되지만, 삽입/삭제/수정 속도는 느려짐
- 저장 공간의 효율이 떨어짐
- 테이블이 크고 복잡해져 유지보수가 어려움
- 과도한 반정규화는 오히려 성능을 저하시킴
반정규화의 적용순서
| 순서 | 설명 |
| 반정규화 대상 조사 | - 자주 사용하는 테이블에 접근하는 프로세스의 수가 많고 항상 일정 범위만을 조회하는 경우 - 테이블에 대량의 데이터가 있고, 대량의 데이터 범위를 자주 처리하는 경우 - 통계 정보를 필요로 할 때 - 지나치게 많은 조인이 걸려 있을 때 |
| 다른 방법으로 유도 | - 성능을 고려한 뷰를 생성하고, 뷰를 통해 접근하게 함으로 성능저하 위험 예방 - 인덱스나 클러스터링을 통한 성능 향상 - 파티셔닝 고려 - 애플리케이션의 로직을 변경하여 성능 향상 |
| 반정규화 수행 | - 반정규화를 수행한다. |
참고
[데이터베이스] 제 3, 4, 5, 보이스코드 정규형 (velog.io)
[데이터베이스] 제 3, 4, 5, 보이스코드 정규형
제 3, 4, 5 그리고 보이스코드 정규형에 대해 알아봅니다.
velog.io
'개발 지식 기록 > 북스터디' 카테고리의 다른 글
| DB - 인덱스(index) (0) | 2024.02.23 |
|---|---|
| 메모리 (0) | 2024.02.08 |
| TCP/IP 4계층 모델 (0) | 2024.02.01 |
| [디자인 패턴] 팩토리 패턴 (0) | 2024.01.26 |
| [스프링 부트 핵심 가이드] 13. 서비스의 인증과 권한 부여 (0) | 2023.10.15 |